
最近,有同学向我咨询如何为 Kubernetes集群选择合适的网络插件,以及不同网络插件之间的实现原理及差异是什么。说实话,这个问题让我一时难以回答,毕竟在 CNCF 的生态体系中有很多网络插件,例如 Calico、Flannel、Cilium、Kube-OVN 等,令人眼花缭乱。
即便是同一个网络插件,也存在多种组网模式,比如直接路由、bridge、IPIP、VXLAN、eBPF 等,每种实现方式都有着各自独特的技术特性和应用场景。
面对如此复杂的情况,实在难以用三言两语说清楚。
接下来我计划以 Calico 网络插件为例,通过多篇文章,深入剖析各种组网模式的实现原理,并探讨它们各自的适用场景,最后再结合客户的真实使用场景,详细阐述如何选择合适的网络插件和组网模式。
Kubernetes网络基础回顾
在介绍 Calico 之前,我们先来回顾一下 Kubernetes 的网络。Kubernetes 的网络模型包含以下部分:
- IP 地址分配:集群内每个 Pod 会被分配一个唯一的 IP 地址。在 Pod 内部,所有容器共享同一个网络命名空间,不同容器之间的进程可以通过localhost或127.0.0.1进行通信;
- Pod 间通信:集群内任意两个 Pod 之间可以互相通信,无论它们是否在同一节点,均无需代理或地址转换(NAT)即可实现通信;
- 服务与 Pod 通信:集群通过 Service 为后端的 Pod 提供一个统一的访问入口,每个 Service 拥有稳定的 IP 地址,即使后端各个 Pod 动态变化,集群也可以通过 Service IP 将流量按照负载均衡策略分发到后端的各个 Pod 中;
- Pod 与集群外部通信:集群通过 Gateway API 提供的高级路由管理能力,让集群内部的 Service 能对外暴露,方便外部服务访问集群资源;
- 网络策略管控:集群可以使用 NetworkPolicy 精细管控 Pod 之间以及 Pod 与外部服务的流量。通过设置访问规则,保障网络安全,实现业务隔离;
Kubernetes仅定义了网络模型,自身并没有实现容器的网络连接,而是通过容器网络接口CNI来调用网络插件,由网络插件完成容器网络连接的具体配置和搭建工作。
Calico 作为一款优秀的网络插件,不仅可以为 Kubernetes 集群实现 IP 地址分配和 Pod 间高效通信,还提供了强大的网络策略功能,例如网络隔离和访问控制。
此外,Calico 可以与 Kubernetes 的 Service 和 Gateway API 紧密配合,通过构建稳定的网络拓扑,优化 Pod 与服务之间以及 Pod 与集群外部的通信,从而提升整个 Kubernetes 集群的网络性能和安全性。
Calico 组件与架构
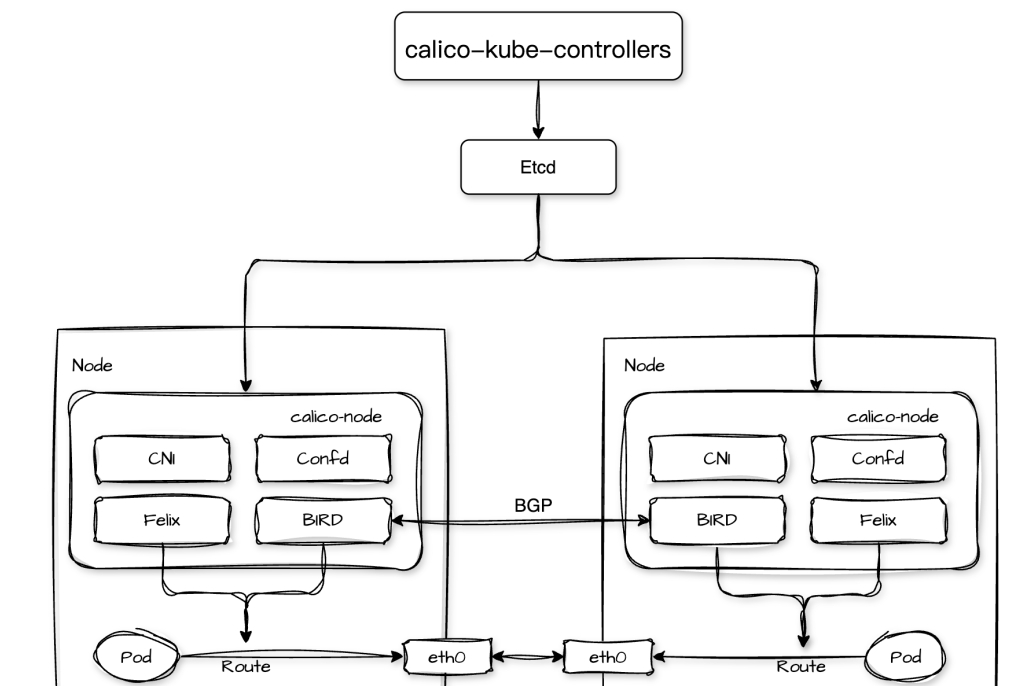
Calico 的核心组件包括calico-kube-controllers、calico-node以及etcd等:
1.calico-kube-controllers以 Deployment 形式部署,负责同步网络策略、管理IP池、监控节点状态等重要的任务;
2.calico-node以守护进程的方式在 Kubernetes 集群的每个节点上运行,负责执行 Calico 的网络策略、管理路由和配置网络接口等关键任务。其内部包括多个进程:
- Felix:负责节点上的网络接口管理、路由配置和访问控制列表(ACL)管理,它会从监控集群中的网络策略和配置,并根据这些信息在集群节点上动态地配置网络接口和路由规则;
- BIRD:BGP 客户端,包括 bird(用于IPv4)和 bird6(用于IPv6),BGP 客户端会从 Felix 获取路由信息并使用边界网关协议(Border Gateway Protocol,BGP)分发给集群中其他节点的 BIRD 进程来交换路由信息,实现 Pod 跨节点的网络通信;
- Confd:负责监听集群中配置的变化,当检测到配置更新时会重新生成相关的配置文件,并通知 BIRD 等进程重新加载配置;
- CNI:负责为 Kubernetes 集群提供 Calico 网络,在 Pod 创建和销毁时根据 Calico 的网络配置为容器配置网络接口。包括为集群中每个 Pod 分配唯一的 IP 地址、将 Pod 的网络接口连接到 Calico 网络、在 Pod 的网络接口中配置相应的访问控制规则等;
3.etcd:作为 Calico 的存储系统,负责存储 Calico 的网络配置、策略规则、IP 地址分配等数据;
Calico 支持多种组网方式,包括:BGP、IPIP、VXLAN 等,本期我们先从 Calico 最基础的 BGP 模式开始说起。
Calico BGP 模式
BGP(Border Gateway Protocol,边界网关协议)是一种基于 TCP 的应用层去中心化自治路由协议,主要用于在不同自治系统(AS)之间交换路由信息。通过 TCP 连接,不同自治系统之间的 BGP 路由器可以建立邻居关系。
建立连接后,双方会交换 BGP 路由信息,包括本地网络的可达性信息以及到达其他网络的路径信息。
当 BGP 路由器收到多条到达同一目标的路由时,会根据一系列路径属性(如 AS 路径长度、下一跳地址、本地优先级等)和策略来选择最优路径。
在 Calico 网络中,集群的节点可以充当虚拟路由器(vRouter)的角色,随后通过 BGP 协议将运行在节点上的 Pod 网络路由信息向整个 Calico 网络传播,这样,集群中的 Pod 就可以通过主机路由实现高效、透明的网络连接。
在深入探讨 Calico BGP 模式下 Pod 的网络通信转发过程之前,我们需要提前准备一个安装好 Calico 网络插件的 Kubernetes 集群,并将 BGP 模式设置为启动状态。
搭建 Kubernetes 集群
社区中搭建 Kubernetes 的工具非常多,这里我使用的是kebekey,操作过程如下:
#安装kubekey $exportKKZONE=cn $curl -sfL https://get-kk.kubesphere.io | VERSION=v3.0.13 sh - #安装 Kubernetes 集群和 Calico 插件,并启用 BGP 模式 $cat > cluster.yaml <<EOF apiVersion: kubekey.kubesphere.io/v1alpha2 kind: Cluster metadata: name: zlw-cluster spec: hosts: - {name: 10-23-14-110, address: 10.23.14.110, internalAddress: 10.23.14.110, user: root, sshKey: "~/.ssh/id_rsa"} - {name: 10-23-14-111, address: 10.23.14.111, internalAddress: 10.23.14.111, user: root, sshKey: "~/.ssh/id_rsa"} - {name: 10-23-14-112, address: 10.23.14.112, internalAddress: 10.23.14.112, user: root, sshKey: "~/.ssh/id_rsa"} - {name: 10-23-14-113, address: 10.23.14.113, internalAddress: 10.23.14.113, user: root, sshKey: "~/.ssh/id_rsa"} - {name: 10-23-14-114, address: 10.23.14.114, internalAddress: 10.23.14.114, user: root, sshKey: "~/.ssh/id_rsa"} - {name: 10-23-14-115, address: 10.23.14.115, internalAddress: 10.23.14.115, user: root, sshKey: "~/.ssh/id_rsa"} roleGroups: etcd: - 10-23-14-110 - 10-23-14-111 - 10-23-14-112 control-plane: - 10-23-14-110 - 10-23-14-111 - 10-23-14-112 worker: - 10-23-14-113 - 10-23-14-114 - 10-23-14-115 controlPlaneEndpoint: domain: lb.kubesphere.local address: "" port: 6443 kubernetes: version: v1.32.0 clusterName: cluster.local network: plugin: calico kubePodsCIDR: 10.233.0.0/16 kubeServiceCIDR: 10.96.0.0/16 calico: ipipMode: Never vxlanMode: Never bgp: enabled: true asNumber: 64512 peerSelector: all() EOF $kk create cluster -f cluster.yaml -y --debug
在本次实验中,我准备了6台机器,其中10-23-14-110、10-23-14-111和10-23-14-112作为集群的 master 节点,10-23-14-113、10-23-14-114、10-23-14-115作为 worker 节点。
经过以上操作后,我们可以得到一个安装好 Calico 网络插件的 Kubernetes 集群。随后在节点10-23-14-110上执行以下命令查看 Calico 的网络状态:
$ kubectl get IPPool default-ipv4-ippool -oyaml apiVersion: crd.projectcalico.org/v1 kind: IPPool metadata: name: default-ipv4-ippool spec: allowedUses: - Workload - Tunnel blockSize: 24 cidr: 10.233.0.0/16 ipipMode: Never natOutgoing:true nodeSelector: all() vxlanMode: Never $ calicoctl node status Calico process is running. IPv4 BGP status +--------------+-------------------+-------+----------+-------------+ | PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO | +--------------+-------------------+-------+----------+-------------+ | 10.23.14.111 | node-to-node mesh | up | 12:31:31 | Established | | 10.23.14.112 | node-to-node mesh | up | 12:31:30 | Established | | 10.23.14.113 | node-to-node mesh | up | 12:31:32 | Established | | 10.23.14.114 | node-to-node mesh | up | 12:31:31 | Established | | 10.23.14.115 | node-to-node mesh | up | 12:31:31 | Established | +--------------+-------------------+-------+----------+-------------+ IPv6 BGP status No IPv6 peers found.
Calico 网络插件提供了 Overlay Network 和 Underlay Network 两种网络方案。其中 Overlay Network 的实现包括 IPIP 和 VXLAN 模式,而 Underlay Network 的实现则是 BGP 模式。
在当前的 Calico IPPool 配置中,ipipMode和vxlanMode属性均为Never,说明没有使用 IPIP 和 VXLAN 模式,而是使用 BGP 模式,即采用的是 Underlay Network。
此外,我们可以看到10.23.14.110节点上的 Calico 进程正在运行,并且已经和10.23.14.111至10.23.14.115这5台机器建立了 IPv4 BGP 连接。PEER TYPE为node-to-node mesh说明当前 BGP 使用了 Full Mesh 模式(全互连模式),即集群内各个节点两两之间都建立了 BGP 连接。
为了让更加清晰地说清楚Calico BGP 在 FullMesh 模式下的网络通信原理,我将分别从同节点和不同节点这两个维度展开 Pod 的通信过程。
同节点 Pod 网络通信
首先,我在集群中部署了两个副本,让它们都运行在节点10-23-14-110上:
$ kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES zlw-01 1/1 Running 0 1h 10.233.133.2 10-23-14-110 <none> <none> zlw-02 1/1 Running 0 1h 10.233.133.3 10-23-14-110 <none> <none>
可以看到,副本zlw-01和zlw-02的 PodIP 分别是10.233.133.2和10.233.133.3。接下来,我们执行以下命令检测网络的连通性:
$ kubectlexec-it zlw-01 -- ping -c 1 10.233.133.3 PING 10.233.133.3 (10.233.133.3) 56(84) bytes of data. 64 bytes from 10.233.133.3: icmp_seq=1 ttl=63 time=0.149 ms --- 10.233.133.3 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.075/0.075/0.075/0.000 ms
在副本zlw-01中访问zlw-02的 PodIP 时能够正常获得响应,说明它们的网络通信是通畅的。那么,同节点的两个副本,它们之间流量的转发过程是怎么样的呢?
容器到主机
我们先来看一下副本zlw-01的网络设备:
$ kubectlexec-it zlw-01 -- ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: eth0@if3120: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 4a:8d:0e:93:6a:39 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.233.133.2/32 scope global eth0 valid_lft forever preferred_lft forever
命令ip a是ip addr的缩写,通过查看其输出,我们可以看到副本zlw-01的 eth0 网卡地址是10.233.133.2,这个地址正是zlw-01的 PodIP 地址。
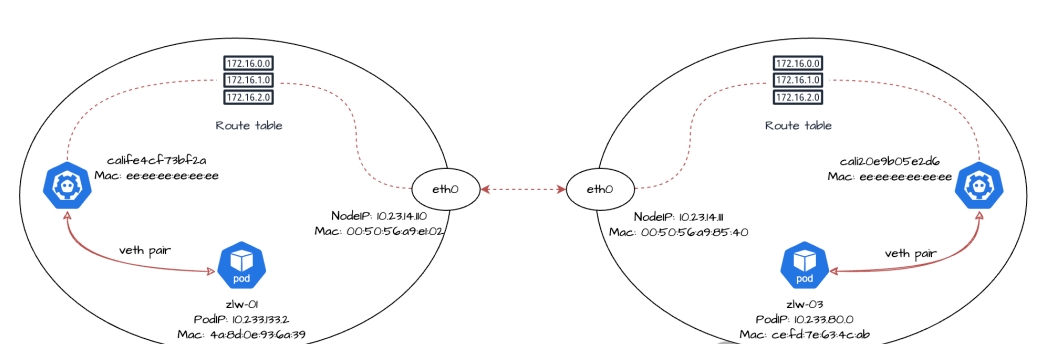
而容器的 eth0 网卡不会单独出现,在创建容器时 Calico 会为容器生成一对虚拟以太网卡(veth pair),其中一端在容器内部,即我们看到的 eth0,而另外一端在节点中,通常以 cali 为前缀命名,并且有一个索引编号。例如eth0@if3120表示副本zlw-01中容器的 eth0 网卡与节点中索引编号为 3120 的网卡是一对 veth pair。
接下来我们再看一下副本zlw-01的路由表信息:
$ kubectlexec-it zlw-01 -- ip r default via 169.254.1.1 dev eth0 169.254.1.1 dev eth0 scope link $ kubectlexec-it zlw-01 -- route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0 169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
default via 169.254.1.1 dev eth0是一条默认路由,充当兜底的角色。当系统需要将数据包发到一个目标地址,但在路由表中找不到精确匹配的条目时,就会使用默认路由。169.254.1.1 dev eth0 scope link属于直连路由,表明169.254.1.1和 eth0 处于同一链路,数据包可以在这个链路上直接传输,无需通过其他网关。
在 Calico 中,169.254.1.1充当了默认网关的角色。当容器中产生发往路由表中未明确匹配外部地址(即目标地址是 0.0.0.0)的数据包时,这些数据包会经过容器内的 eth0 网卡,随后到达节点的 cali 网卡,接着被转发至默认网关169.254.1.1,最后由网关负责后续的转发。
前面我们知道,运行在节点10-23-14-110上的副本zlw-01,其容器的 eth0 网卡与节点中索引编号为 3120 是一对 veth pair,因此我们可以在10-23-14-110执行以下命令找到对应的 cali 网卡:
$ ip a | grep -A 3 3120 3120: calife4cf73bf2a@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 2 inet6 fe80::ecee:eeff:feee:eeee/64 scope link valid_lft forever preferred_lft forever
从输出的结果可以知道,索引为 3120 的 cali 网卡具体名称是calife4cf73bf2a。这个网卡没有 IP 地址,它的MAC 地址是ee:ee:ee:ee:ee:ee。
接下来,我们可以使用 tcpdump 命令来监听网卡calife4cf73bf2a流量情况:
$ tcpdump -i calife4cf73bf2a -ne 03:24:05.122338 4a:8d:0e:93:6a:39 > ee:ee:ee:ee:ee:ee, ethertype ARP (0x0806), length 42: Request who-has 169.254.1.1 tell 10.233.133.2, length 28 03:24:05.122390 ee:ee:ee:ee:ee:ee > 4a:8d:0e:93:6a:39, ethertype ARP (0x0806), length 42: Reply 169.254.1.1 is-at ee:ee:ee:ee:ee:ee, length 28 03:24:05.122407 ee:ee:ee:ee:ee:ee > 4a:8d:0e:93:6a:39, ethertype ARP (0x0806), length 42: Request who-has 10.233.133.2 tell 10.23.14.110, length 28 03:24:05.122416 4a:8d:0e:93:6a:39 > ee:ee:ee:ee:ee:ee, ethertype ARP (0x0806), length 42: Reply 10.233.133.2 is-at 4a:8d:0e:93:6a:39, length 28
从监听的输出结果中我们可以得知:
1.副本zlw-01所在的eth0 网卡(IP 地址是10.233.133.2,MAC 地址4a:8d:0e:93:6a:39)发起了一次 ARP 请求,用以查询169.254.1.1的 MAC 地址,节点10-23-14-110的 cali 网卡calife4cf73bf2a(MAC 地址为ee:ee:ee:ee:ee:ee)对请求进行了响应,确认169.254.1.1的 MAC 地址是ee:ee:ee:ee:ee:ee;
2.节点10-23-14-110通过calife4cf73bf2a网卡,向副本zlw-01的 eth0 网卡发起了 ARP 请求,用于查询10.233.133.2的 MAC 地址。副本zlw-01的 eth0 网卡(MAC 地址是4a:8d:0e:93:6a:39)对请求进行了响应,确认10.233.133.2的 MAC 地址是4a:8d:0e:93:6a:39;
这里我们可能会有疑问:作为 Calico 默认网关的169.254.1.1,它的 MAC 地址为什么会是ee:ee:ee:ee:ee:ee呢?
实际上169.254.1.1是 Calico 为容器网络虚拟出来的默认网关 IP,并非真实的物理设备 IP。
当zlw-01通过 eth0 网卡发起 ARP 请求查询默认网关169.254.1.1的 MAC 地址时,在节点上与 eth0 对应的 cali 网卡calife4cf73bf2a会通过代理 ARP 响应容器的 ARP 请求,并返回自身的 MAC 地址,即ee:ee:ee:ee:ee:ee。
这个设计是 Calico 利用 cali 网卡作为容器与节点的虚拟连接桥梁(即 veth pair 的对端),通过代理 ARP 可以让容器发往169.254.1.1的流量被封装为目的 MAC 地址为ee:ee:ee:ee:ee:ee的数据帧,数据帧会从容器的 eth0 网卡到达节点的 cali 网卡,进而可以使用节点的路由转发能力实现网络通信。
为了验证节点10-23-14-110上的 cali 网卡calife4cf73bf2a是否启用代理 ARP 功能,我们可以在节点上执行以下命令
$ cat /proc/sys/net/ipv4/conf/calife4cf73bf2a/proxy_arp 1
返回值为1即代表 cali 网卡calife4cf73bf2a已经启用代理 ARP 功能,可以代答 ARP 请求。
接下来,我们在使用 tcpdump 命令继续监听副本zlw-01流量的同时,在另一个新的终端执行以下命令:kubectl exec -it zlw-01 — ping -c 1 10.233.133.3,随后我们可以看到 tcpdump 监听到以下结果:
10:20:32.661779 4a:8d:0e:93:6a:39 > ee:ee:ee:ee:ee:ee, ethertype IPv4 (0x0800), length 98: 10.233.133.2 > 10.233.133.3: ICMPechorequest, id 12, seq 1, length 64 10:20:32.661882 ee:ee:ee:ee:ee:ee > 4a:8d:0e:93:6a:39, ethertype IPv4 (0x0800), length 98: 10.233.133.3 > 10.233.133.2: ICMPechoreply, id 12, seq 1, length 64
可以看到,当副本zlw-01向zlw-02发送 ICMP 请求时,流量从容器内的 eth0 网卡发出,经 veth pair 到达节点的 cali 网卡calife4cf73bf2a,此时源 IP 是10.233.133.2(副本zlw-01的 IP 地址),目标 IP 是10.233.133.3(副本zlw-02的 IP 地址),源 MAC 地址是4a:8d:0e:93:6a:39(副本zlw-01中 eth0 网卡的 MAC 地址),目标 MAC 地址是ee:ee:ee:ee:ee:ee(副本zlw-01的 cali 网卡calife4cf73bf2a的 MAC 地址),最后流量到达节点。
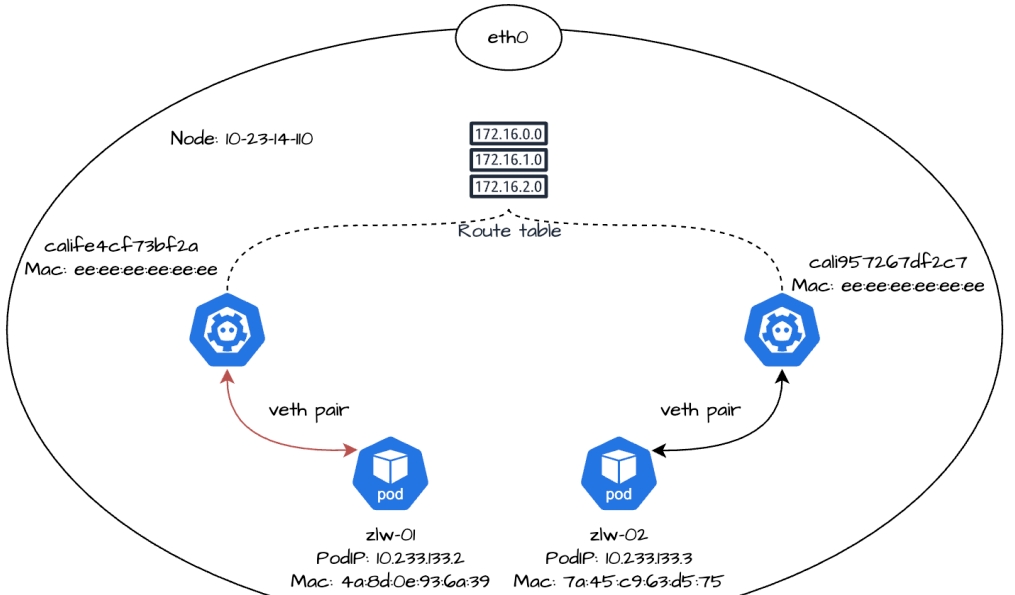
接下来,我们再来看一下副本zlw-01的流量如何从节点上转发到同节点上的副本zlw-02。
主机到容器
先看一下副本zlw-02的网络设备:
$ kubectlexec-it zlw-02 -- ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: eth0@if3121: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether 7a:45:c9:63:d5:75 brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.233.133.3/32 scope global eth0 valid_lft forever preferred_lft forever
随后我们可以在节点中找到索引编号为 3121 的网卡设备:
ip a | grep -A 3 3121 3121: cali957267df2c7@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 3 inet6 fe80::ecee:eeff:feee:eeee/64 scope link valid_lft forever preferred_lft forever
因此可以确认,节点10-23-14-110上的 cali 网卡cali957267df2c7和副本zlw-02的 eth0 网卡是一对 veth pair。
随后我们查看节点10-23-14-110的路由表,可以看到以下内容:
$ ip route 10.233.133.2 dev calife4cf73bf2a scope link src 10.23.14.110 10.233.133.3 dev cali957267df2c7 scope link src 10.23.14.110
10.233.133.2和calife4cf73bf2a分别是副本zlw-01的 PodIP 和 cali 网卡,10.233.133.3和cali957267df2c7则分别是副本zlw-02的 PodIP 和 cali 网卡。scope link说明是直连路由,意味着副本zlw-01和zlw-02的 cali 网卡处于同一个节点节点的链路上。
当10.233.133.2访问10.233.133.3时,由于它们在同一个链路中,数据包可以直接通过 MAC 地址在二层链路上进行传输,无需经过额外的网关或 NAT 处理。
发往10.233.133.3的数据包,从zlw-01的 eth0 网卡发出,经过对端的calife4cf73bf2a网卡后进入节点,然后在节点的二层网络中转发到zlw-02的cali957267df2c7网卡。
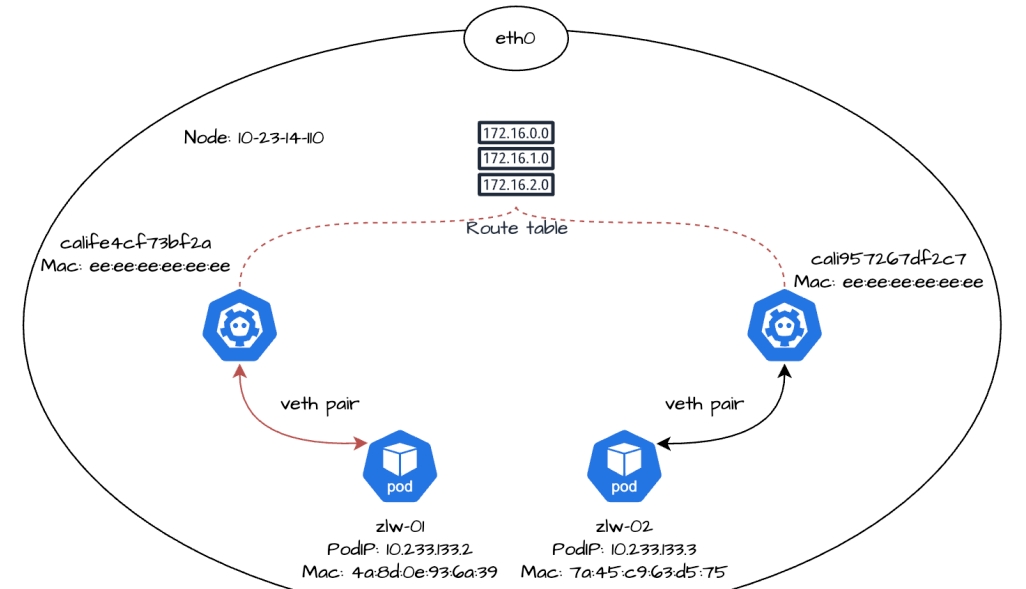
最后流量会通过cali957267df2c7网卡到达对端的zlw-02的 eth0 网卡,从而进入到容器zlw-02中。我们可以在副本zlw-02的 eth0 网卡中监听到以下数据:
$ kubectlexec-it zlw-02 -- tcpdump -i eth0 -ne tcpdump: verbose output suppressed, use -v[v]...forfull protocol decode listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes 04:29:50.685440 ee:ee:ee:ee:ee:ee > 7a:45:c9:63:d5:75, ethertype IPv4 (0x0800), length 98: 10.233.133.2 > 10.233.133.3: ICMPechorequest, id 17, seq 1, length 64 04:29:50.685460 7a:45:c9:63:d5:75 > ee:ee:ee:ee:ee:ee, ethertype IPv4 (0x0800), length 98: 10.233.133.3 > 10.233.133.2: ICMPechoreply, id 17, seq 1, length 64
可以看到,当流量进入到副本zlw-02后,此时源 IP 是10.233.133.2(副本zlw-01的 IP 地址),目标 IP 是10.233.133.3(副本zlw-02的 IP 地址),源 MAC 地址是ee:ee:ee:ee:ee:ee(副本zlw-02的 cali 网卡cali957267df2c7的 MAC 地址),目标 MAC 地址是7a:45:c9:63:d5:75(副本zlw-02中的 eth0 网卡的 MAC 地址)。
总的来说,对于相同节点 Pod 的网络通信,流量会从一个副本的 eth0 网卡发出,通过 veth pair 到达节点上对端的 cali 网卡。由于两个 cali 网卡属于同一个节点的虚拟链路(通过 veth pair 与对应的容器直连),因此数据帧会通过 MAC 地址在二层链路上直接传输,节点内核会在二层网络通过虚拟链路的点对点连接将数据帧转发到另外一个副本的 cali 网卡。
随后目标 cali 网卡会通过 veth pair 将数据帧转发到对应容器的 eth0 网卡,最后,响应的数据包再通过原路返回,完成整个通信的过程。
介绍完同节点 Pod 之间的网络通信,我们再来看看不同节点上 Pod 之间的通信过程有哪些相同点和不同点。
不同节点 Pod 网络通信
现在,我们在集群中新增一个名为zlw-03的副本,并将其与已有的副本zlw-01分别部署在不同的节点上。
$ kubectl get pods -owide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES zlw-01 1/1 Running 0 1h 10.233.133.2 10-23-14-110 <none> <none> zlw-02 1/1 Running 0 1h 10.233.133.3 10-23-14-110 <none> <none> zlw-03 1/1 Running 0 1h 10.233.80.0 10-23-14-111 <none> <none>
接下来,我们来看一下副本zlw-03的网络设备和路由规则:
$ kubectlexec-it zlw-03 -- ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever 2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop state DOWN group default qlen 1000 link/ipip 0.0.0.0 brd 0.0.0.0 3: eth0@if328463073: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether ce:fd:7e:63:4c:ab brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet 10.233.80.0/32 scope global eth0 valid_lft forever preferred_lft forever $ kubectlexec-it zlw-03 -- ip r default via 169.254.1.1 dev eth0 169.254.1.1 dev eth0 scope link $ kubectlexec-it zlw-03 -- route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0 169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
随后在节点10-23-14-111中查看副本zlw-03的 cali 网卡:
$ ip a | grep -A 3 328463073 328463073: cali20e9b05e2d6@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000 link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netnsid 0 inet6 fe80::ecee:eeff:feee:eeee/64 scope link valid_lft forever preferred_lft forever
因此,我们可以看到副本zlw-03的 PodIP 是10.233.80.0,eth0 网卡的 MAC 地址是ce:fd:7e:63:4c:ab。veth pair 对端的 cali 网卡名称是cali20e9b05e2d6,MAC 地址是ee:ee:ee:ee:ee:ee。
容器到主机
我们在副本zlw-01向副本zlw-03发起网络请求:
$ kubectlexec-it zlw-01 -- ping -c 1 10.233.80.0 PING 10.233.80.0 (10.233.80.0) 56(84) bytes of data. 64 bytes from 10.233.80.0: icmp_seq=1 ttl=62 time=0.382 ms --- 10.233.80.0 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 0.382/0.382/0.382/0.000 ms
流量会从副本zlw-01的 eth0 网卡发出,经过对端的calife4cf73bf2a网卡,最终到达节点10-23-14-110,这个过程和我们之前讨论的流量从容器到主机的的方式没有差别。
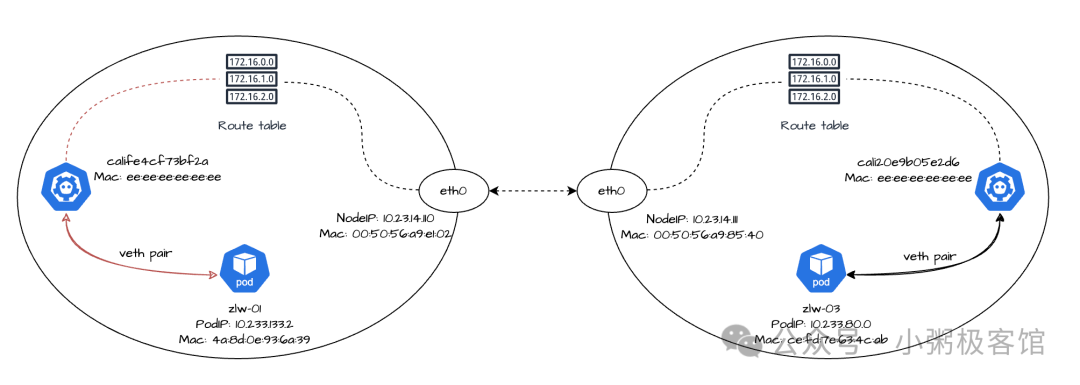
接下来我们重点看一下流量如何在主机之间进行转发。
主机到主机
先查看节点10-23-14-110的路由规则:
$ ip route 10.233.133.2 dev calife4cf73bf2a scope link src 10.23.14.110 10.233.133.3 dev cali957267df2c7 scope link src 10.23.14.110 10.233.80.0/24 via 10.23.14.111 dev eth0 proto bird
和之前相比,主机中新增了一条路由规则:10.233.80.0/24 via 10.23.14.111 dev eth0 proto bird。这条规则的意思是:对于目标地址在10.233.80.0/24网段内的数据包,设备将通过 eth0 接口发给下一跳10.23.14.111。这条路由是 Calico 的 BGP 客户端 BIRD 组件获取的。
接下来我们再来看一下节点10-23-14-110eth0 的网卡信息:
ip a show eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:50:56:a9:e1:02 brd ff:ff:ff:ff:ff:ff inet 10.23.14.110/24 brd 10.23.14.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::250:56ff:fea9:e102/64 scope link valid_lft forever preferred_lft forever
可以看到节点10-23-14-110的 MAC 地址是00:50:56:a9:e1:02。
接下来,节点10-23-14-110将会通过 ARP 协议解析下一跳10.23.14.111的 MAC 地址。其中,10.23.14.111是节点10-23-14-111eth0 网卡的 IP 地址,我们可以在节点10-23-14-111上执行以下命令:
ip a show eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:50:56:a9:85:40 brd ff:ff:ff:ff:ff:ff inet 10.23.14.111/24 brd 10.23.14.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::250:56ff:fea9:8540/64 scope link valid_lft forever preferred_lft forever
可以看到节点10-23-14-111的 MAC 地址是00:50:56:a9:85:40。
在执行kubectl exec -it zlw-01 — ping -c 1 10.233.80.0命令后,我们可以在节点10-23-14-111中通过 tcpdump 命令监测到以下数据:
tcpdump -i eth0 -ne | grep"10.233.80.0" tcpdump: verbose output suppressed, use -v or -vvforfull protocol decode listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes 02:19:54.751970 00:50:56:a9:e1:02 > 00:50:56:a9:85:40, ethertype IPv4 (0x0800), length 98: 10.233.133.2 > 10.233.80.0: ICMPechorequest, id 23, seq 1, length 64 02:19:54.752045 00:50:56:a9:85:40 > 00:50:56:a9:e1:02, ethertype IPv4 (0x0800), length 98: 10.233.80.0 > 10.233.133.2: ICMPechoreply, id 23, seq 1, length 64
可以看到,副本zlw-01访问zlw-03的流量,会通过节点10-23-14-110发送到10-23-14-111,这个过程中:
- 源 IP 是zlw-01的 PodIP10.233.133.2;
- 源 MAC 地址是10-23-14-110节点eth0网卡对应的MAC 地址00:50:56:a9:e1:02;
- 目标 IP 是zlw-03的 PodIP10.233.80.0;
- 目标 MAC 地址是10-23-14-111节点eth0网卡对应的MAC 地址00:50:56:a9:85:40;
当流量进入到节点10-23-14-111后,再从对应的 cali 网卡将流量转发到副本zlw-03中。
主机到容器
我们看一下节点10-23-14-111上关于副本zlw-03的路由规则:
ip r | grep 10.233.80.0 10.233.80.0 dev cali20e9b05e2d6 scope link src 10.23.14.111 blackhole 10.233.80.0/24 proto bird
可以看到,发往10.233.80.0网段的数据包将通过设备cali20e9b05e2d6进行发送,而cali20e9b05e2d6就是副本zlw-03在节点上的 cali 网卡,后续流量会通过这个 cali 网卡到达副本zlw-03的 eth0 网卡,最近进入容器。这个过程和我们之前讨论的流量从主机到容器的方式没有差别。
总结
经过我前面的介绍,相信大家已经清楚了 Calico BGP 在 Full Mesh 模式下同节点和不同节点上 Pod 的网络通信原理:各节点通过 BGP 协议建立对等连接实现路由信息的交换,随后通过 Linux veth pair 实现容器和主机网络的通信,再通过主机路由实现数据包在节点之间的转发。
在 Full Mesh 模式下,每个节点都会和其他节点建立起 BGP 对等连接,然而 BGP 连接的数量会随着节点数量按照 n*(n-1)/2 的规模增长,这种增长方式在节点数量较大时会给集群的网络带来较大的压力,导致路由更新的效率会显著降低。
因此,Full Mesh 模式通常更适合节点规模相对较小的中小型集群,官方推荐适用的节点规模最好是在 100 个以内。如果我们需要在大规模的集群上部署时,可以选择反射器模式(Route Reflector),或者在本地部署场景下与机架顶部(ToR)路由器建立对等连接的方式部署。
在反射器模式中,部分节点被设置为路由反射器,这些路由反射器之间构建成网状结构,而其他节点只需要跟部分路由反射器(通常为2个,以实现冗余)建立对等连接。
这种方式相较于 Full Mesh 模式,每个节点的 BGP 对等连接数量会大幅减少,因此反射器模式比 Full Mesh 模式更适合大规模集群,缺点是它的配置也相对来说更复杂。
本期关于 Calico BGP 模式的内容分享就分享到这里,后续我会继续介绍 Calico 在 IPIP 和 VXLAN 模式下的网络通信过程,以及如何为集群选择合适的网络模式,我们下期再见!